
Nouvelle mission chez EDF
Missions et références
Depuis juin 2012 : Architecture technique SAP chez EDF :
- Etude de fusion des 8 instances SAP FI/CO pour la comptabilité EDF
- Etude d’un parcours de migration vers une solution de Cloud Computing pour SAP
- Rédaction de DATs (Document d'Architecture Technique) décrivant l'interface entre les besoins métier, les exigences de disponibilité/sécurité/confidentialité, les fonctionnalités du progiciel et les contraintes de production de l'infogérant
- Migration de 90 instances SAP : ECC6, BW, Sap Content Server, SAP PI, SAP GRC, Solution Manager : Interface entre la MOA EDF, la DSI EDF et l'infogérant
De février à mai 2012 : Groupe Casino à Saint-Etienne avec les objectifs suivants :
- Rationaliser et améliorer les procédures de copie/refresh d'instances SAP
- Gérer le projet de migration OS/DB de Windows/SQL Server vers Aix/DB2 de l'instance SAP orienté FI/CO
- Mener des campagnes de mesure et d'amélioration de performances SAP
- Qualifier et spécifier la mise en œuvre du monitoring des Business Processes avec Solution Manager
- S'intégrer à l'équipe de support N3 et y apporter son expertise
Décembre2011-Janvier 2012 : OTAN CEPMA (Central Europe Pipeline Management Agency)
Mise en oeuvre d'un PRA pour la production Oracle/SAP
Réalisation technique :
- Reprise de l’instance de production sur un serveur de secours
- Import ZFS des volumes répliqués au niveau de la baie de disques Compellent
- Paramétrage Oracle et SAP
- Recette technique et fonctionnelle
De janvier à septembre 2011 : Tereos (Industrie du sucre et des céréales)
Définition de l'architecture technique permettant d'exécuter les nouveaux environnements de production
- SAP ECC6 et Business Objects BI 4.0 : 40 000 SAPs
- Autres environnements SAP : GRC, APO, TDMS
- CI/DB Serveurs Sun M9000 + SAN HDS AMS2500
Gestion du projet de déploiement
- Rédaction du Plan Qualité de Projet
- Rédaction et suivi de planning
- Coordination des intervenants
Après une première partie qui relate des travaux de recherche académiques qui sous-tendent et justifient l'appartion de SAP HANA. Nous allons décrire comment ces travaux de recherche se déclinent en pratique à travers l'offre SAP
Et SAP HANA dans tout ça ?
Tout ce que je viens de décrire provient, pour une bonne part, des travaux de l’Institut Hasso Plattner, et la solution SAP HANA s’est inspirée de ces recherches, à la fois d’un point de vue de la conception du produit et de la stratégie globale SAP :
- D’un point de vue technique en orientant sa gamme logicielle vers une fonctionnalité de traitement de l’information en temps réel sans passer par l’étape parasite du Dataware House
- D’un point de vue commercial en promouvant sa propre solution de base de données qui évite de rétribuer son premier concurrent : Oracle, mais aussi les autres éditeurs de base de données (Microsoft pour SQL Server et IBM pour DB2) qui tirent parti du marché SAP sans apporter de valeur ajoutée pour l’utilisateur. En effet, du point de vue de SAP comme de l’utilisateur final, il n’y a pas de valeur ajoutée spécifique à avoir un SAP sur Oracle plutôt que sur SQL Server ou DB2. Les performances et les fonctionnalités de la solution globale sont équivalentes.
Les travaux de recherche de l’Institut Hasso Plattner, les évolutions technologiques, les tendances du marché des composants (la baisse de prix de la mémoire), et la stratégie concurrentielle de SAP l’ont conduit à développer sa plate-forme du futur qu’il est maintenant possible de commencer à expérimenter. Pour un acteur du marché aussi présent que SAP, la difficulté est de proposer de nouvelles solutions qui tirent parti de travaux de recherche tels que ceux que nous venons de parcourir, tout en préservant les investissements de ses clients et donc en définissant une évolution sans rupture. On ne s’étonnera donc pas que SAP HANA ressemble plus à un compromis et un assemblage de technologies déjà existantes, plutôt qu’à une plate-forme révolutionnaire. De plus, on a vu que sur les quatre piliers qui soutiennent la vision de Hasso Plattner, trois d’entre eux souffrent de contreparties dont il faut réduire les effets, en face des avantages qu’ils apportent :
- La base de données orientées colonnes est nettement avantageuse en lecture. Elle le paie par des performances moins avantageuses en écriture
- La base de données « insert only database » n’est pas adaptée à une activité de forte écriture. Les chiffres produits par SAP ne sont pas représentatifs d’une activité composite
- La base de données en mémoire doit pouvoir être sécurisée sans que le prix à payer soit pénalisant pour sa performance globale.
Les CPUS multi-cœurs qui forment le quatrième pilier sont d’ores et déjà la norme des microprocesseurs et constituent une base solide sur laquelle SAP peut s’appuyer pour construire ses nouvelles architectures.
SAP HANA est donc un compromis entre ces différents facteurs. Sa définition officielle est : “The SAP HANA database is a hybrid in-memory database that combines row-based, column-based, and object-based database technology. It is optimized to exploit the parallel processing capabilities of modern multi-core CPU architectures. With this architecture, SAP applications can benefit from current hardware technologies.” Comme il est difficile de trouver sur les sites SAP sur quelle base technologique il repose, on se contentera de ce que nous dit Wikipédia à ce sujet :
SAP HANA is the synthesis of three separate products – TREX, P*Time and MaxDB.
- TREX (Text Retrieval and Extraction) is a search engine and began in 1996 as a student project at SAP in collaboration with DFKI. TREX became a standard component in SAP NetWeaver in 2000. In-memory attributes were added in 2002 and columnar data store was added in 2003, both as ways to enhance performance.
- In 2005 SAP acquired Menlo Park based Transact in Memory, Inc. With the acquisition came P*Time, an in-memory light-weight online transaction processing (OLTP) RDBMS technology with a row-based data store.
- MaxDB (formerly SAP DB), a relational database coming from Nixdorf via Software AG (Adabas D) to SAP, was added to TREX and P*Time to provide persistence and more traditional database features like backup.
Ces informations nous suffisent pour comprendre comment SAP HANA a été conçu et quel est son avenir prévisible :
- Le mélange de base de données en colonne et en ligne indique un compromis entre les ambitions de performance en lecture et les contraintes en écriture. Il est probable que cette division entre deux types de table et la technique de partition de tables, dont on a vu l’intérêt, va conduire les équipes de développement SAP à réviser profondément le schéma de leur base de données ;
- Le mélange de MaxDB et de Transact In Memory est également un compromis entre les attentes espérées d’une base de données en mémoire et les contraintes de continuité auxquelles ce type de technologie ne permet pas encore de répondre. Ce mélange de deux types de bases de données ressemble à ce que fait Oracle avec la base de données mémoire Timesten acquise en 2005 ;
- La technique de base de données « insert only » a disparu et n’est pas utilisée pour l’instant ;
On a donc un schéma et une organisation des données hybride, en quatre parties, gérées par un processus nommé « index server » :
- Les données au format « ligne » optimisées pour les opérations en écriture, et entièrement chargées en mémoire ;
- Les données au format colonne, manipulées par le troisième composant cité plus haut, c'est-à-dire TREX, qui, d’un moteur de recherche, a évolué vers une base de données orientée colonne ;
- Les données objet, qu’il est difficile de qualifier plus précisément, et qui seraient exploitées par un mécanisme dérivé du SAP Live Cache ;
- Des données sur disque pour celles qui sont plus anciennes et moins appelées.
Ajoutons à cela l’architecture matérielle qui doit être certifiée par SAP et qui repose sur des processeurs Intel Xeon de la famille E7. Certaines présentations avant-vente de SAP affirmaient que SAP HANA avaient l’exclusivité d’instructions CPU spécifiques et présentes uniquement sur cette Appliance. Je n’ai pas eu confirmation de cette information. Les documents Intel font état d’un jeu d’instructions permettant d’optimiser la recherche et la décompression de données. Les développeurs SAP ont pu tirer parti de ce jeu d’instructions pour développer des algorithmes efficaces. Nulle part, il n’est question d’exclusivité.
Les constructeurs certifiés par SAP sont : Cisco, Dell, Fujitsu, Hitachi, HP, IBM et NEC. Chacun propose des configurations de différentes puissances. Voici, à titre d’exemple, la gamme SAP HANA de IBM :

La configuration matérielle ne doit pas négligée. IBM affiche que les performances mémoire varient de 1 à 0,29 suivant la configuration choisie en nombre de DIMMs, de contrôleurs et de bus mémoire.
Les constructeurs matériels, qui sont souvent plus prudents que les éditeurs, ne sous-estiment pas le risque de perte de données chargées en mémoire, lors d’un crash de serveur. Par exemple, IBM préconise de sauvegarder les pages modifiées toutes les 5 minutes. Les logs sont écrits sur un stockage persistant, de manière synchrone, et la transaction n’est achevée qu’au retour de l’acquittement de ce stockage. Là encore, la configuration matérielle peut être décisive entre les différents types de stockage disponibles et leur affectation judicieuse, comme dans ce schéma proposé par IBM.

Ces mécanismes de sauvegarde sont proclamés « transparents pour l’application » par SAP. C’est, en tous cas, un indicateur de performances qui mérite d’être surveillé avec attention.
Support et utilisation de SAP HANA dans les architectures actuelles
Parmi les configurations supportées par SAP HANA, deux architectures se détachent particulièrement :
- L’architecture « Side car » ;
- SAP HANA comme base de données pour SAP BW ;
Le Side-Car
Il ne faut pas se fier à cet intitulé particulièrement stupide. Les gens du marketing se sont encore surpassés !! Un « side-car » est propulsé par la moto ; il ne lui apporte aucune aide, au contraire !
SAP HANA, en mode side-car, est là pour accélérer les processus, et non pas pour se faire traîner, heureusement ! Quoi qu’il en soit, en voici le schéma de principe :

Il n’y a pas de BW dans ce schéma, qu'il ne faut pas confondre avec un BWA. Le principal intérêt de cette architecture est de rendre plus performante l’utilisation du module CO-PA (Controlling Profit Analysis). Bien que CO-PA soit un module ERP, c’est une fonctionnalité très proche de ce que l’on peut faire sur un BW. Il n’est donc pas étonnant que SAP le propose, au sein de ce qu’ils appellent des Rapid Deployment Solutions (RDS). La source de données est bien un ERP, les données sont chargées dans SAP HANA, permettant au RDS CO-PA d’attaquer des structures de données ayant tous les avantages offerts par la solution SAP HANA.
SAP HANA sur BW
Il s’agit cette fois-ci de monter un BW au-dessus de SAP HANA en tant que base de données. Le schéma ci-dessous représente cette architecture :

Par rapport à un existant SAP, deux possibilités sont ouvertes :
- Créer une nouvelle instance BW au-dessus de SAP HANA ;
- Migrer un BW déjà existant (en version 7.3 SPS5 minimum) vers la base de données SAP HANA. Cette migration se fait par les mêmes mécanismes qu’un changement de base pour n’importe quel produit SAP, en suivant les principes d’une OS/DB Migration.
Mécanismes de réplication
Ces deux architectures finales ne répondent pas à la question de l’alimentation de la base SAP HANA, que ce soit dans le cas du side-car ou de BW sur SAP HANA. Dans les deux cas de figure, SAP HANA est une base de données secondaire qui doit être alimentée par une instance transactionnelle : le plus souvent une autre instance SAP de type transactionnel, ou d’autres sources de données non SAP. Pour cela, SAP propose différentes techniques illustrées par le schéma suivant :

La plus complète de ces techniques est la « Trigger-Based Replication ». C’est la seule qui supporte tous les types d’application SAP (à partir de la 4.6 C), et non-SAP. Elle nécessite un composant supplémentaire : une instance SLT (SAP Landscape Transformation) :
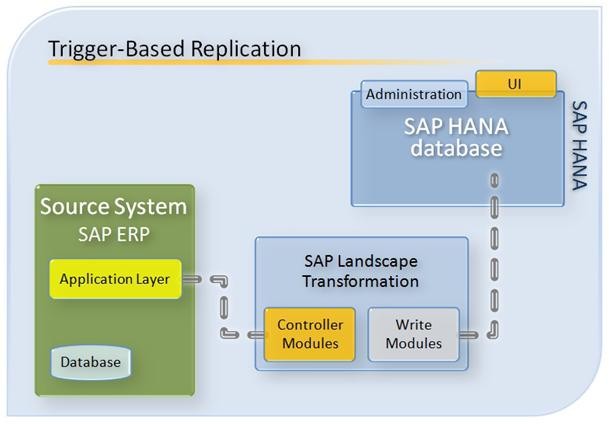
Je ne dispose pas de données précises concernant le temps de chargement initial, ni l’impact sur le système source du mécanisme de « trigger », qui va propager les modifications effectuées sur la source vers SAP HANA, en passant par le serveur SLT. Ce serveur SLT est basé sur la technologie TDMS. Une fois le mécanisme enclenché, SAP affirme que les données sont disponibles dans SAP HANA, et donc dans l’instance BW, en « quasi temps-réel ». Là encore, des retours clients chiffrés seraient les bienvenus.
Avons-nous répondu à la question ?
Notre question d’origine était : SAP HANA va-t-il tuer SAP BW ? Considérant les possibilités actuelles, la réponse est non. En tous cas, il ne l’a pas tué, puisque l’on vient de voir que son utilisation privilégiée se faisait en tant que moteur de base de données pour SAP BW. Pour autant a-t-on répondu aux inconvénients majeurs des datawarehouse :
- La séparation entre la source de données et son traitement décisionnel ?
Non, l’architecture SAP HANA avec BW conserve la source de données transactionnelles, le mécanisme intermédiaire de type ETL, qui est ici joué par le serveur SLT, et l’instance
spécialisée BW. Il semblerait que l’on n’ait rien gagné.
- Le retard entre les données analysées par SAP BW par rapport aux données transactionnelles qui en sont la source ?
Oui, en partie. Le mécanisme de réplication « quasi temps réel », s’il représente toujours une étape, pour le moment incontournable, permet de raccourcir de manière
importante ce décalage dans le temps.
- L’amélioration des performances ?
Oui, si l’on en croit les témoignages de client ayant expérimenté SAP HANA. Il existe même un club 10K et 100K qui recense des cas où les temps de réponse ont été multipliés par
10 000 et même 100 000. Ces témoignages sont disponibles sur le site : http://www.experiencesaphana.com/welcome
- La possibilité de configurer rapidement de nouveaux rapports et de nouvelles sources de données ?
Non. On a vu que l’on conserve le mécanisme de type ETL qui suit les étapes classiques d’un projet de développement, recette et mise en production. Il n’est toujours pas
possible, pour l’utilisateur final, de choisir le format de ses rapports ou d’attaquer les données de son choix. Néanmoins, il est juste de rendre compte de certaines expériences faisant état
d’un plus grande facilité d’utilisation du SAP HANA Studio par comparaison avec du développement sur BW.
La roadmap SAP
Pourtant, l’ambition de SAP reste la même, et son analyse n’a pas changé. L’architecture BW n’est qu’un compromis provisoire. Après cette première étape, permettant de raccourcir le chemin entre la source de données transactionnelles et le traitement BW, la figure finale telle qu’elle est imaginée par SAP devrait ressembler à cela :

On aurait ainsi une seule base de données SAP HANA, qui serait attaquée par divers types d’application :
- Business Object, parce que c’est déjà vrai dans les solutions existantes et que c’est l’outil parfait à fournir aux utilisateurs pour qu’ils puissent construire facilement leurs requêtes ;
- Des serveurs d'application ECC, parce que c’est l’objectif final qui répond à la vision de Hasso Plattner et à la stratégie de SAP telle que j’ai pu la décrire et la comprendre ;
- Conserveront-ils des serveurs d'application BW ? Tout dépend des questions de compatibilité et des fonctionnalités de Business Object que je ne connais pas assez pour en juger ;
- On peut aussi se poser la question de l’unicité de la base de données SAP HANA, si elle sera capable de tout mutualiser et si elle comportera un ou plusieurs schémas de données.
Concernant le ou les schémas de données, nous avons vu que la mise en œuvre de base de données orientée colonne, de partition de tables, de conservation de certaines tables au format ligne imposent un gros travail de design de la nouvelle base de données SAP HANA. Et si la base de données subit cette refonte, il faudra aussi modifier les programmes ABAP et Java. Nous avons vu que SAP a déjà livré un nouveau module CO-PA qui puisse se connecter à SAP HANA. Si SAP veut généraliser à tous ses modules l’adaptation fait pour CO-PA, il lui a faudra faire un gros effort de développement. Heureusement, parmi les plusieurs dizaines de milliers de tables de la base de données, les dizaines de milliers de programmes, seuls quelques centaines forment le cœur de l’activité d’une instance SAP. On peut néanmoins penser que ce travail demandera plusieurs années avant d’être complètement achevé. Un horizon 2014-2015 semble raisonnable.
C’est alors que, si tout va bien, SAP aura complètement cassé la barrière entre l’instance transactionnelle de type ECC et les fonctionnalités d’analyse décisionnelle. Le décisionnel pourra se faire directement sur des données « chaudes », exactement dans l’état réel du métier, en tous cas tel qu’il est représenté dans l’instance ECC. Plus de décalage dans le temps, et plus de transformation/déformation de données. Tout sera là, disponible pour l’utilisateur, et la question se déportera alors sur la puissance et la souplesse de l’outil de requêtage.
Conclusion
Au terme de cette étude, on peut conclure sans grand risque que l’arrivée de SAP HANA va représenter une évolution majeure et un réel progrès dans le monde SAP. À chacun d’en déduire les conséquences par rapport à sa propre implémentation SAP. Il me semble pourtant, qu’étant donnée la rupture que cela provoque et la place centrale que cette technologie représente pour la stratégie de SAP, il est nécessaire de se familiariser dès maintenant avec ce nouvel outil. On a vu que les constructeurs proposent tous des plates-formes de différentes dimensions, allant de l’extra small à l’extra large. Il y a de quoi faire son marché, et se familiariser avec ce que cela implique en termes de de développement de requêtes et de procédures d’exploitation.
Je terminerai par une anecdote qui m’est arrivée chez un de mes anciens clients, un grand groupe de distribution. Ils sont intéressés par SAP HANA, et sont même un des premiers clients à avoir investi sur cette technologie. Discutant avec un de leurs responsables IT, celui-ci me déclara : « Ce que l’on veut, c’est pouvoir remonter l’ensemble des tickets de caisse de tous nos magasins, tous les quarts d’heure, pour avoir une vision quasi temps réel de l’activité ». Comme je lui demandais ce qu’ils pouvaient faire de cette information : « Et si vous apprenez que les ventes de pots de Nutella sont en train d’exploser dans tel magasin du côté de Lyon, qu’est-ce que vous allez faire ? Vous pouvez réagir aussi vite que l’information qui vous arrive ? »
Dans un monde complètement informatisé, on peut s’amuser (si l’on peut dire) à développer des systèmes bousiers de transaction à haute fréquence. L’information boursière arrive à la milliseconde, et les systèmes analysent cette information pour donner des ordres de bourse dans les mêmes délais. Dans cette autre sorte de « casino », on a perdu tout contact avec le monde réel. Comme tout est automatisé et programmé sans plus d’intervention humaine, toute lourdeur a disparu. Sans réclamer qu’une chaîne de grands magasins, ou toute autre activité du monde réel parvienne à ces excès, on peut quand même s’interroger sur l’usage qui va être fait de l’information, devenue connaissance exploitable, avec des systèmes comme SAP HANA, arrivés à maturité.

Il reste à gérer la prise de décision, les moyens dont on dispose pour agir sur l’offre de produits et les délais de réaction de cette chaîne de retour. Car si l’information arrive en « temps réel » et que la réaction reste lente, on n’aura pas gagné grand-chose. En automatisme, on parle de rétroaction ou de feedback. Et là, ce n’est pas SAP HANA qui pourra aider.
Écrire commentaire
Eric D. (samedi, 20 octobre 2012 16:59)
René,
Excellent travail de synthèse ! Un "must be read" comme souvent !
Quelques retours d'expérience chiffrés dès 2013, sans doute.
Eric
René (lundi, 22 octobre 2012 08:40)
Merci Eric pour ces commentaires encourageants. Ce sera peut-être toi qui donnera des retours chiffrés, si jamais SAP HANA se met en place chez ton client.
A bientôt,
René
vja@akimbo-solutions.com (jeudi, 13 mars 2014 15:07)
Site landaile.com
Evangelina Bode (vendredi, 03 février 2017 10:19)
Wow, awesome blog format! How long have you been running a blog for? you make running a blog look easy. The whole glance of your website is magnificent, let alone the content material!
Bart Hollins (dimanche, 05 février 2017 05:21)
I got this site from my friend who shared with me about this web page and now this time I am browsing this site and reading very informative articles or reviews here.
Denyse Olsen (dimanche, 05 février 2017 18:44)
Having read this I believed it was extremely enlightening. I appreciate you taking the time and energy to put this informative article together. I once again find myself personally spending a significant amount of time both reading and posting comments. But so what, it was still worthwhile!