
Nouvelle mission chez EDF
Missions et références
Depuis juin 2012 : Architecture technique SAP chez EDF :
- Etude de fusion des 8 instances SAP FI/CO pour la comptabilité EDF
- Etude d’un parcours de migration vers une solution de Cloud Computing pour SAP
- Rédaction de DATs (Document d'Architecture Technique) décrivant l'interface entre les besoins métier, les exigences de disponibilité/sécurité/confidentialité, les fonctionnalités du progiciel et les contraintes de production de l'infogérant
- Migration de 90 instances SAP : ECC6, BW, Sap Content Server, SAP PI, SAP GRC, Solution Manager : Interface entre la MOA EDF, la DSI EDF et l'infogérant
De février à mai 2012 : Groupe Casino à Saint-Etienne avec les objectifs suivants :
- Rationaliser et améliorer les procédures de copie/refresh d'instances SAP
- Gérer le projet de migration OS/DB de Windows/SQL Server vers Aix/DB2 de l'instance SAP orienté FI/CO
- Mener des campagnes de mesure et d'amélioration de performances SAP
- Qualifier et spécifier la mise en œuvre du monitoring des Business Processes avec Solution Manager
- S'intégrer à l'équipe de support N3 et y apporter son expertise
Décembre2011-Janvier 2012 : OTAN CEPMA (Central Europe Pipeline Management Agency)
Mise en oeuvre d'un PRA pour la production Oracle/SAP
Réalisation technique :
- Reprise de l’instance de production sur un serveur de secours
- Import ZFS des volumes répliqués au niveau de la baie de disques Compellent
- Paramétrage Oracle et SAP
- Recette technique et fonctionnelle
De janvier à septembre 2011 : Tereos (Industrie du sucre et des céréales)
Définition de l'architecture technique permettant d'exécuter les nouveaux environnements de production
- SAP ECC6 et Business Objects BI 4.0 : 40 000 SAPs
- Autres environnements SAP : GRC, APO, TDMS
- CI/DB Serveurs Sun M9000 + SAN HDS AMS2500
Gestion du projet de déploiement
- Rédaction du Plan Qualité de Projet
- Rédaction et suivi de planning
- Coordination des intervenants
La montée en puissance de SAP HANA est le résultat de travaux de recherche au niveau de la base de données ainsi que de l’arrivée de nouvelles possibilités offertes par les évolutions du matériel. Dans une première partie, je passe en revue ces travaux de recherche. Une deuxième partie sera consacrée à SAP HANA en tant qu’il tire parti de ces travaux tout en tâchant de conserver la compatibilité avec les plates-formes existantes.
Pourquoi le datawarehouse ?
Aujourd’hui les données de l’entreprise sont réparties sur plusieurs systèmes et base de données. Leur cohérence est menacée et l’on sait comme il est difficile de mener au bout un projet d’unification des « master data ». Ne parlons pas des données transactionnelles qui bougent sans arrêt avec l’activité de l’entreprise. De plus, et depuis les travaux de Bill Inmon, qui a popularisé le concept de datawarehouse, les données fraîches et transactionnelles sont localisés dans des systèmes de type OLTP alors que les données d’analyse et de décision en sont extraites pour être retravaillées, transformées et chargées dans des systèmes OLAP. Le schéma classique de ce chemin de données est représenté ci-dessous :

Un schéma qui, bien que classique n’en est pas moins complexe d’un point de vue logiciel et onéreux d’un point de vue matériel en multipliant les serveurs et les volumes disques pour une donnée qui, fondamentalement est restée la même depuis la source, même si le dataware permet de l’examiner sous différents axes d’analyse et apporte donc une connaissance supplémentaire. Il n’en reste pas moins que l’utilisateur final se plaint souvent de la lourdeur et de la lenteur du processus. De plus, il n’est pas maître de toutes les transformations effectuées, et plus d’un met en doute l’intégrité des données qu’il manipule. Cela fait donc deux inconvénients majeurs qui handicapent cette technologie : l’écart temporel entre les données du dataware et l’écart potentiel d’un point de vue de l’intégrité de ces données.
On peut alors se demander pourquoi cette technique est si répandue, voire presque universelle. Je ne parlerai ici que des applications SAP, mais la remarque s’applique à toute autre ligne de produit. Pourquoi donc, dans le monde SAP, comme dans le reste, a-t-on vu apparaître des instances BW en sus des instances ERP transactionnelles. On peut distinguer deux raisons majeures :
- Le besoin de séparer des tâches d’extraction et de calcul lourd, des tâches de mises à jour et de lectures légères. En effet, à l’époque de la mise en œuvre des BW, les ordinateurs n’avaient pas la puissance nécessaire pour supporter ces deux types de tâches. C’est pourquoi, l’on réservait, et l’on réserve encore la journée pour l’activité transactionnelle (quand les employés sont au travail) et la nuit à l’activité batch (la nuit applicative)
- La structure de la base de données OLTP n’est pas adaptée à ces demandes de requêtage complexe
C’est donc pour contourner ces inconvénients que la technique du datawarehouse s’est répandue et s’est déclinée chez SAP avec les solutions BW (Business Warehouse).
Le dataware n’est qu’une solution de contournement
Néanmoins, et ici c’est Hasso Plattner (un des fondateurs de SAP) qui s’exprime : “I always believed the introduction of so-called data ware-houses was a compromise. The exibility and speed we gained had to be paid for with the additional management of extracting, and loading data, as well as controlling the redundancy. For many years, the discussion seemed to be losed and enterprise data was split into OLTP and OLAP. OLTP is the necessary prerequisite for OLAP, however only with OLAP, companies are able to understand their business and come to conclusions about how to steer and change course “
Or, et c’est la vision de Hasso Plattner, deux avancées technologique doivent permettre de se passer de cette solution, qui reste à ses yeux, une solution de contournement que nous pouvons désormais supprimer. Les deux avancées technologiques sont :
- Les bases de données orientées colonne
- Les CPUs multicore et multithread
Ces deux techniques doivent permettre de raccourcir le chemin entre la donnée brute et la donnée intelligible et exploitable : raccourcir le chemin entre la donnée non structurée et la connaissance permettant de prendre des décisions suivant le paradigme classique DIKW :
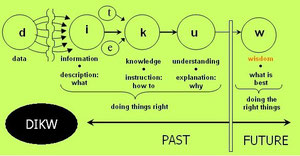
Base de données orientée colonne
La base de données colonne est essentiellement une autre manière de stocker l’information. L’exemple donné par Wikipedia est le plus parlant :
« Par exemple, une base de données pourrait contenir cette table :
|
EmpId |
Nom |
Prénom |
Salaire |
|
1 |
Durant |
Jacques |
40000 |
|
2 |
Dupont |
Marie |
50000 |
|
3 |
Martin |
Jeanne |
44000 |
Cette table simple inclut un identifiant d'employé (EmpId), des champs Nom et Prénom, et un salaire.
Cette table peut être présente dans la mémoire de l'ordinateur (RAM) ou sur son disque dur. Bien que la mémoire RAM et les disques durs fonctionnent différemment, le système d'exploitation les abstrait. Ainsi, la table à deux dimensions vue par l'utilisateur est représentée par le système de gestion de la base de données comme une suite d'octets pour que le système d'exploitation puisse l'écrire en mémoire ou sur le disque.
Une table orientée données sérialise toutes les valeurs d'une ligne ensemble, puis les valeurs de la ligne suivante, etc.
1,Durant, Jacques,40000;2,Dupont, Marie,50000;3,Martin, Jeanne,44000;
Une base de données orientée colonne sérialise les valeurs d'une colonne ensemble, puis les valeurs de la colonne suivante, etc
1,2,3;Durant,Dupont,Martin;Jacques,Marie,Jeanne;40000,50000,44000; »
Une base de données colonne est lue colonne par colonne quand l’autre modèle est lu ligne à ligne, comme nous-mêmes quand nous lisons un texte. La base de données orientée colonne présente dès lors deux avantages majeurs :
- Elle accélère la lecture et évite de passer par des index ; les index deviennent même inutiles. Si l’on considère la requête suivante qui est très largement représentative d’une requête provenant de SAP : select c1, c2, c5 from table where c2 < x. On comprend tout de suite l’avantage à « descendre » d’un seul coup la colonne pour trouver les valeurs qui nous intéressent et récupérer ensuite les valeurs de c1 et c2.
- D’autre part, étant donné que les données d’une même colonne sont forcément du même type (CHAR, INTEGER, TIMESTAMP) et qu’elles sont souvent dupliquées, on peut profiter d’un taux de compression très favorable. Supposons une table des ventes comportant des articles, des clients et des prix, il est clair que le nombre de clients sera très inférieur au nombre de lignes de la table. Pour la colonne client, on retrouvera sans doute un grand nombre de fois le client « client1 » pour chaque achat effectué par ce dernier. Il devient alors facile de compresser la colonne client de telle manière à éviter d’occuper autant de place qu’il n’y a d’occurrences de « client1 »
Les CPUs multi-cœurs
Naguère la puissance CPU était quasiment proportionnel le à sa fréquence d’horloge. Puis, on s’est aperçu , aux alentours des 3Ghz, que l’on s’approchait de limites physiques, principalement en terme de dissipation calorique. On s’est également aperçu qu’il ne servait à rien de chercher à monter encore en fréquence dans la mesure où les accès mémoire ne suivaient pas le même rythme d’accélération. On avait un moteur surpuissant qui n’était plus alimenté en données et passaient par une multitude de cycles à vide faute de données à traiter. D’où l’idée de paralléliser les traitements et de développer les architectures multi-cœurs. Pendant qu’un cœur travaille, les autres peuvent aller cherche les données dont ils ont besoin, puis prendre la main pour laisser le temps au premier cœur d’écrire les données venant d’être calculées. De cette manière on peut encore gagner en puissance de traitement, sous réserve que la couche logicielle sache exploiter cette fonctionnalité offerte par les architectures multi-cœurs. Or, typiquement, SAP était un progiciel qui ne savait pas du tout exploiter le parallélisme des nouvelles CPUs. C’est ainsi que, travaillant aux débuts des années 2000 chez SunMicroSystems, j’ai pu observer que cette évolution vers les architectures multi-cœurs, dont Sun était le pionnier, nous désavantageait beaucoup é dans le monde SAP. Alors que nos concurrents (Intel et IBM) continuaient à monter en fréquence leurs CPUs, Sun faisait le pari du multi-cœurs. Un pari gagné aujourd’hui, mais par les autres, Sun ayant disparu. En effet, le multi-cœurs était très mal exploité par des progiciels comme SAP qui n’utilise qu’un seul cœur par « work process ». Et un cœur Sun parmi les 16 disponibles était unitairement beaucoup plus lent qu’une CPU avec un seul cœur mais beaucoup plus rapide. Les 15 autres cœurs ne servaient à rien.
La combinaison des deux
Aujourd’hui, l’architecture multi-cœurs est partout, et miraculeusement, si l’on peut dire, la base de données orientée colonne peut en tirer partie. Le balayage de plusieurs colonnes d’une base de données est exactement le type d’activité qu’il va être très facile de paralléliser. On va pouvoir distribuer la tâche entre cœurs, sans besoin de forte synchronisation, et donc profiter à la fois du gain offert par la base de données orientée colonne et des CPUs multi-cœurs.
Et les écritures ?
Arrivé à ce stade, il semblerait bien qu’on ait résolu, sur le papier au moins, le problème du décalage dans le temps et de la pauvreté de l’information que l’on peut manipuler avec une application BW. Toutes choses égales par ailleurs, le saut à accomplir est comparable à celui réalisé par Google dans le domaine de la recherche sur Internet. Qui se souvient des anciens moteurs de recherche (Altavista, Lycos,..) en a gardé le souvenir d’un rendu très lent et très peu pertinent. Il a suffi d’utiliser Google une fois pour abandonner définitivement ces anciens outils. Tout à coup, on obtenait une réponse quasi instantanée et surtout, bien classée et très pertinente. Les outils de reporting basés sur les technologie de datawarehouse sont dans un état pré-Google. L’alliance des CPUs multi-cœurs et de la base de données orientée colonne doit permettre d’effectuer ce saut. Sauf que, l’on n’a toujours pas résolu la question de l’écriture des données. On a imaginé une architecture matérielle et logicielle qui nous permet d’accélérer nos besoins de reporting, mais on ne sait pas encore comment alimenter ce nouveau dispositif. Car si la base de données orientée colonne, permet d’accélérer les requêtes qui sont elles aussi orientées colonnes, il n’en est pas de même pour les écritures qui sont plutôt orientées lignes.
Il y a trois types d’écriture dans une base de données : les insertions, les mises à jour et les destructions (insert, update, delete)
Reprenant l’exemple de la table des ventes, une nouvelle vente va se traduire par l’insertion d’une ligne comprenant, la liste des articles, le client, les adresses de livraison, de facturation, de délais et toute autre information qui permet de qualifier complètement l’opération de vente. Va-t-on payer en insertion ce que l’on a gagné en lecture ? La réponse apportée par les laboratoires de recherche SAP est beaucoup moins convaincante sur ce sujet. Elle tient en trois axes complémentaires :
1 – Une insertion de lignes n’est jamais (ou très rarement) une insertion de tous les champs de la ligne. Notre nouvelle vente va très probablement concerner un client déjà existant de même adresse de facturation et de livraison (les master data). Pour accélérer le processus d’insertion, il faut alors partitionner la table entre les données transactionnelles et les master data de telle manière à n’écrire que dans la première partition et mettre en place un jeu de pointeurs pour assurer la cohérence de l’ensemble. De cette manière, on limite le nombre d’écritures nécessaires. Par ailleurs, Hasso Plattner affirme que la création d’agrégats « on the fly » permet d’optimiser les insertions restantes et sont mêmes plus performantes que des insertions dans une base orientée ligne. Faute de comprendre comment et pourquoi, je me contenterais de présenter le schéma censé le démontrer :
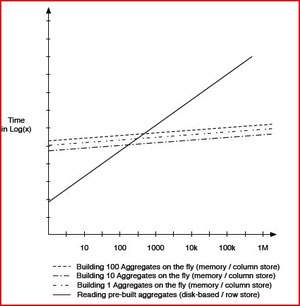
2 – Il y a un fort intérêt fonctionnel à ne pas faire de mise à jour, ni de destructions. La raison en est très simple. Ne jamais modifier ni détruire permet de conserver un historique de la donnée. Ce type de base de données est appelé « insert only database ». Cette approche a été adoptée par PostGreSQL dès 1987. L’idée est d’identifier les différentes versions de l’information avec un champ « timestamp ». Par défaut, le moteur ramène la plus récente, mais il est toujours possible de récupérer les anciennes versions en précisant une autre date. On en voit tout de suite l’intérêt en termes de récupération d’erreur de saisie. Un autre intérêt est que cette technique permet d’analyser les données suivant un axe des temps qui est naturellement déjà présent dans la base de données.
Face à ces avantages fonctionnels, on devine très vite des inconvénients techniques. Étant donné que l’on ne détruit jamais l’information, le volume de données va augmenter considérablement. SAP donne deux réponses :
- Le partitionnement de tables tel que vu précédemment permet de minorer l’accroissement de volume
- Une étude interne SAP a montré que sur 14 millions d’entêtes de document comptable (la table BKPF) 13 349 389 n’étaient jamais mis à jour, ce qui représente 3,79% du total. Ce faible taux de mise à jour accompagné de technique de compression orientée colonne et du partitionnement de tables aboutit à une augmentation de volume de 15% au lieu des 40% qui auraient pu être craints.
A ces arguments, on me permettra deux remarques :
- La statistique porte sur les entêtes comptables (la table BKPF). On aimerait avoir la même sur la table BSEG qui contient tous les documents comptables liés aux entêtes de la BKPF. On peut penser que le taux de mises à jour est plus important.
- Les table comptables n’on sûrement pas le même taux de mise à jour que des tables de vente, de gestion de stock, ou d’administration des ventes. Ces activités sont beaucoup plus sujettes à de nombreuses écritures que la gestion comptable.
In Memory Database
Il nous reste un dernier niveau de technologie à examiner : la base de données en mémoire ou « In Memory Database ». Car tous ces travaux de recherche de l’Institut Hasso Plattner, et SAP HANA, dont je parlerai bientôt, ne seraient pas complets sans cette couche hardware. Qu’est-ce qu’une base de données en mémoire ? Car, après tout, il ya longtemps que les bases de données classiques utilisent massivement les fonctionnalités de la mémoire de l’ordinateur pour accélérer les accès aux données de la base. Quelle est donc la différence entre une base de données « classique » qui cache des données en mémoire et une base de données en mémoire ?
Une base de données en mémoire est entièrement chargée en mémoire, elle est construite pour ça, de telle façon que ses opérations de lecture/écriture sont programmées pour travailler directement en mémoire. Une base de données classique est écrite pour aller chercher et pour écrire ses données sur disque. Le passage en cache est une étape supplémentaire qui est gérée à la fois par la base de données elle-même et par les routines du système d’exploitation. La base de données en mémoire est donc, depuis la conception, un système de lecture/écriture qui ne connait que la mémoire sans avoir à gérer les écritures disque. Il s’agit donc d’un système intrinsèquement plus rapide. La figure suivante détaille les différentes opérations réalisées par une base de données traditionnelle sur disque :
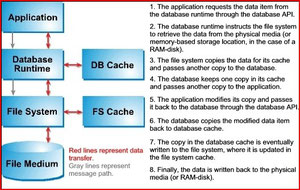
Par contraste, une base de données en mémoire n’effectue qu’un seul transfert de données, n’a pas à attendre l’acquittement de l’écriture au niveau du Systems, et économise ainsi un grand nombre de cycles CPU et même de consommation mémoire.
Qui dit données en mémoire va s’interroger sur la persistance des données en cas de crash. Car il faudra bien s’assurer que les données puissent être préservées en cas de panne matérielle ou logicielle. On retrouve alors des techniques traditionnelles de « snapsots » périodiques sur disque et de mécanismes de type « redo log » permettant de sauvegarder les données et l’activité de la base de données. Les techniques de réplication de bases peuvent aussi être utilisées, soit par transfert d’informations de transactions (« redolog shipping ») soit par synchronisation de cache (à l’image des techniques de Cache Fusion Oracle). Toutes ces techniques de sauvegarde sur disque ou de réplication de mémoire sont revendiquées comme étant « transparentes » pour l’application comme pour l’utilisateur. Des données plus précises seraient les bienvenues pour pouvoir effectuer une comparaison…
A ces fonctionnalités logicielles traditionnelles, et qui ont fait leurs preuves, viennent se greffer des nouveaux types de mémoire :
- Les NVRAM ou mémoire flash qui conservent les données même quand elles ne sont plus alimentées électiquement
- Les feRAM qui offrent le même avantage à partir d’une autre base technologique
- Les PRAM qui exploitent le changement de structure d’un matériau bien choisi pour conserver l’information à froid.
Ce qui reste incontestable est que la mémoire vive a un temps d'accès de quelques dizaines ou centaines de nanosecondes tandis que celui du disque dur est de quelques millisecondes (dix mille à cent mille fois plus). Le disque dur est le seul élément mécanique qui subsiste dans les architectures informatiques. Tous les acteurs du marché ont conscience de ses faiblesses et du taux de panne de ce composant, qui est dans le même rapport que son temps d’accès, en comparaison du stockage en mémoire. Il apparaît inéluctable que ce composant finisse par être remplacé par des techniques plus performantes.
Écrire commentaire
Spars Fassini (jeudi, 27 février 2014 05:31)
Great Topic to read